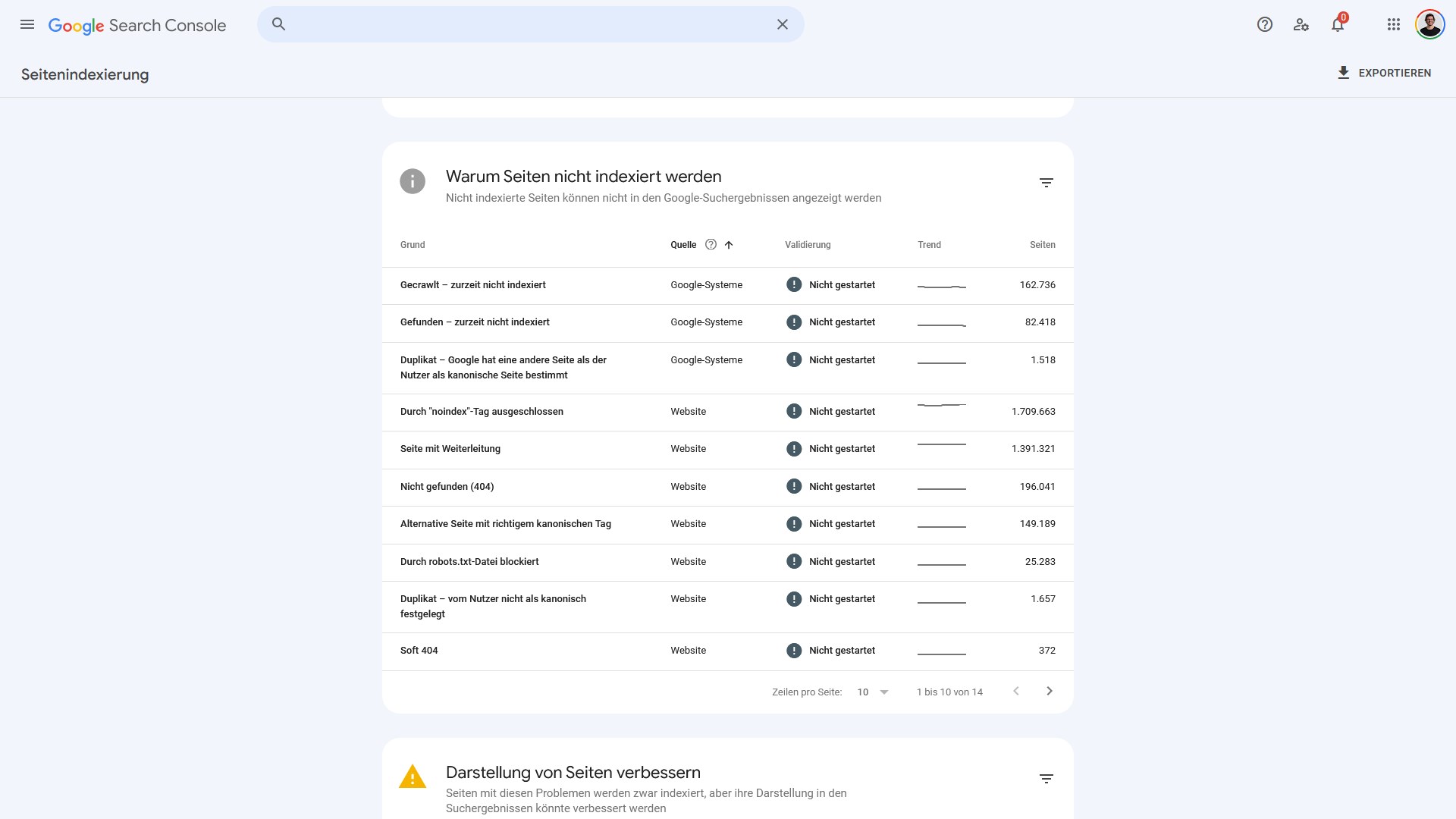
Innerhalb des Indexierungsberichts der Google Search Console sind unter der Quelle „Google-Systeme“ die beiden Fehlergruppen:
- Gecrawlt – zurzeit nicht indexiert
- Gefunden – zurzeit nicht indexiert
die beiden Gruppen, die viele mit Fragen zurücklassen. Denn Google hat sich dazu entschieden, Seiten nicht zu indexieren. Entsprechend können die Seiten nicht über die Google-Suche gefunden werden.
Deine Seite ist von einer oder beiden Gruppen betroffen? Hier erfährst du, wie du mit diesen Problemen umgehst (und wie getIndexed dir bei der Behebung helfen kann).
Inhaltsverzeichnis
Grundlagen von Crawling und Indexierung
Jede Seite (oder auch URL oder „Dokument“) muss den folgenden Prozess durchlaufen, um für ein Ranking in Betracht zu kommen:
- Auffindbarkeit: Die Adresse ist Google bekannt
- Crawlbarkeit: Die Seite konnte von Google erfolgreich besucht werden
- Indexierbarkeit: Die URL darf und wurde von Google dem Index hinzugefügt
Ohne Indexierung kein Ranking, ohne Crawling keine Indexierung, und ohne Auffindbarkeit kein Crawling.
Wenn du mehr wissen möchtest, dann schau im Artikel Google Crawling- und Indexierungsprozess vorbei.
Was bedeutet „Gecrawlt – zurzeit nicht indexiert?“
In der Google-Hilfe heißt es zu dieser Gruppe:
Die Seite wurde von Google gecrawlt, aber nicht indexiert. Sie könnte jedoch in Zukunft indexiert werden. Sie brauchen diese URL nicht noch einmal zum Crawling einzureichen.
Google-Hilfe
Ergo hat Google (bzw. der Googlebot genannte Crawler) auf die Seite zugegriffen, sich aber final gegen eine Indexierung der Seite entschieden. In der Folge kann der Inhalt der betroffenen Seite nicht in der Google-Suche gefunden werden.
Wenn wir uns den weiter oben beschriebenen Crawling- und Indexierungsprozess nochmals vor Auge führen, dann ist bei Schritt 3 etwas nicht nach Plan gelaufen. Google hat – aus welchen Gründen auch immer – die Seite nicht in den Index aufgenommen. Konkret bedeutet das, dass die Adresse gecrawlt wurde und auch potenziell indexiert werden könnte, aber nicht weiter prozessiert wurde.
Bevor wir über die Ansatzpunkte zur Problemlösung übergehen, hier noch ein Lesetipp: Schau doch mal in unserem Artikel zum perfekten Indexierungsstatus vorbei. Eventuell ist es gar kein Problem, dass Seiten (noch) nicht von Google indexiert wurden.
Wie lässt sich „Gecrawlt, zurzeit nicht indexiert“ beheben?
Woran es bei den auf deiner Website betroffenen Seiten genau liegt, kann ohne die Website zu kennen nicht beantwortet werden. Doch es gibt ein paar klassische Probleme, die zur Nicht-Indexierung von Seiten führen. Verallgemeinernd kann gesagt werden, dass Google die Relevanz dieser speziellen Seite als nicht hoch genug eingeschätzt hat.
Aus diesem Grund kommst du bei der Problemlösung nicht an einer Detailbetrachtung der einzelnen Seiten vorbei. Rund um die inhaltlichen Faktoren ist dieser Googles Beitrag deine Zeit wert.
Mögliches Problem #1: Doppelter Inhalt
Von doppelten Inhalten (englisch: Duplicate Content) wird in der Suchmaschinenoptimierung gesprochen, wenn ein Inhalt unter mehreren Adressen zur Verfügung steht.
To-do: Prüfe also, ob die im Bericht genannten Seiten womöglich keine neuen Inhalte bereitstellen.
Mögliches Problem #2: Zu dünne Inhalte
Noch eine weitere Ursache kann etwas mit dem Inhalt auf der Seite zu tun haben: der sogenannte Thin Content. Bei Thin Content geht es nicht primär um die Textlänge, sondern um den Mehrwert. Wenn dieser von Google als nicht ausreichend angesehen wird, dann wird die Seite nicht indexiert.
To-do: Analysiere, ob die Inhalte auf der Seite das Potenzial haben, mit den besten aktuell für das Seitenthema im Netz auffindbaren Adressen zu konkurrieren. Wenn nicht, dann erweitere die Inhalte.
Mögliches Problem #3: Veraltete Inhalte
Nicht nur neue Adressen können gecrawlt, aber nicht (mehr) indexiert sein. Ein Grund dafür können veraltete Informationen auf der Seite sein.
To-do: Schaue, ob die Inhalte auf der Seite noch aktuell sind. Wenn du z.B. veraltete Informationen zu einer Steuerart auf der Website hast, kann das der Grund für eine Nicht-Indexierung sein.
Mögliches Problem #4: Schlechte interne Verlinkung
Google achte nicht nur auf die Relevanz („Worum geht es auf der Seite?“), sondern auch darauf, wie der Inhalt innerhalb der Website und im Netz auffindbar ist.
To-do: Erhebe mit einem Crawler, ob die betroffenen Seiten schlecht innerhalb der Website erreichbar sind und verlinke sie häufiger.
Muss ich etwas tun, um „Gecrawlt, zurzeit nicht indexiert“ zu korrigieren?
Wie im Artikel zum perfekten Indexierungsstatus geschrieben, ist eine Nicht-Indexierung nur dann von Relevanz, wenn davon wichtige Seiten deiner Website betroffen sind. Google selbst sagt, dass du nicht aktiv werden musst – doch es kann eine lange Zeit oder sogar unendlich lang dauern, bis Google von einer Überarbeitung der Seite erfährt. Aus diesem Grund habe ich getIndexed gebaut: Über die Google Indexing API kann ein zeitnahes, erneutes Crawling gestartet werden.
Abseits unseres Tools stehen dir die klassischen Hausmittel für ein (häufigeres) Crawling zur Verfügung:
- Bereitstellung einer (aktuellen) XML-Sitemap inklusive Anmeldung in der Google Search Console
- Beantragung der Indexierung einer einzelnen Seite über die Google Search Console
- Verbesserung der (internen und/oder externen) Verlinkung betroffener Seiten
Was bedeutet „Gefunden – zurzeit nicht indexiert?“
Lass uns auch für dieses Problem wieder auf die Google Search Console-Hilfe schauen. Dort schreibt Google zu dieser Fehlergruppe:
Die Seite wurde von Google gefunden, aber noch nicht gecrawlt. Wird diese Begründung angegeben, hat Google normalerweise versucht, die URL zu crawlen, aber das hätte die Website überlastet. Daher hat Google das Crawling neu geplant. Aus diesem Grund ist das Feld mit dem letzten Crawling-Datum im Bericht leer.
Google-Hilfe
Schauen wir wieder auf den am Anfang des Artikels beschriebenen Crawling- und Indexierungsprozess, dann ist bei dieser Gruppe nach Schritt 1 bereits Schluss. Google kennt die Adressen, hat sich aber gegen einen Besuch der Seiten entschieden.
Wie „Gefunden, zurzeit nicht indexiert“ behoben werden kann
Im Hilfe-Text spricht Google von „normalerweise versucht, die URL zu crawlen“. Ob Google es auch tatsächlich versucht, den Crawl dann aber wegen der angegebenen „Lastprobleme“ abgebrochen hat, kann, muss aber nicht der Fall sein.
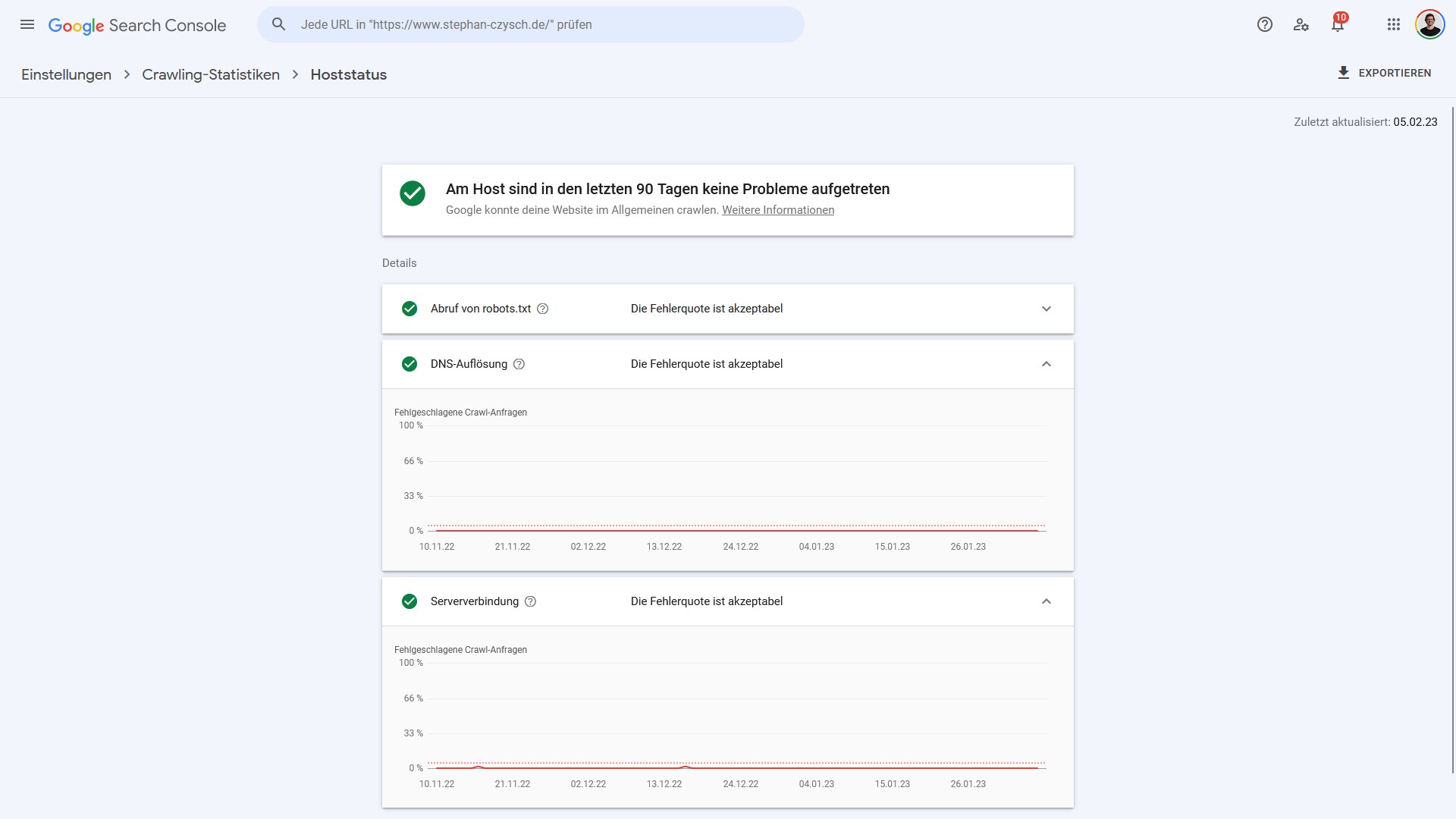
Tipp 1: Serverperformance in der Google Search Console analysieren
Der erste Blick sollte der Serverperformance beziehungsweise möglichen Serverproblemen beim Crawling dienen. Der passende Bericht dafür ist in der Google Search Console unter „Einstellungen“ => „Crawling-Statistiken“ => „Hoststatus“ zu finden.
Sollten hier keine massiven Ausreißer nach oben zu finden sein, kannst du noch einen zusätzlichen Blick auf den Bericht „Core Web Vitals“ in der Google Search Console werfen.
Sollten hier keine massiven Probleme mit langsam ladenden Seiten vorliegen, dann kann eigentlich der Server nicht das Problem sein.
Tipp 2: Erneutes Crawling durch zusätzliche Linksignale erhöhen
Zwischen dem Crawling einer Seite kann schonmal mehrere Wochen oder Monate vergehen. Auch Zeiträume von mehreren Jahren sind (bei großen Seiten) möglich.
Um die Wahrscheinlichkeit eines (erneuten) Crawls zu erhöhen, sollten zusätzliche Signale zu den betroffenen Adressen gesetzt werden. Die Möglichkeiten dafür sind:
- Eintrag der Seiten in XML-Sitemaps (plus Einreichung der Sitemap in der Google Search Console)
- Verbesserung der internen Verlinkung
- Einreichung der Seite über die URL-Prüfung der Google Search Console
Diese drei Methoden erhöhen die Wahrscheinlichkeit eines Crawlings, sind aber nicht die beste Methode. Denn die am besten funktionierende Methode ist die Nutzung der Google Indexing API, z.B. über getIndexed.
Wie getIndexed bei Indexierungsproblemen helfen kann
Das Crawling des Internets ist ein großer Kostenblock für Google. Von daher muss Google mit seinen Ressourcen haushalten und besucht als unwichtig angesehene Adressen unregelmäßig. Im vorherigen Absatz wurde bereits beschrieben, wie du ein erneutes Crawling initiieren kannst.
Die erfolgversprechendste Methode ist die Nutzung der Google Indexing API. Und diese ist der zentrale Baustein von getIndexed. Über die Indexing API ist ein bevorzugtes Crawling von Seiten möglich. Probiere es aus und sichere dir den kostenlosen Probeaccount.