Die erfolgreiche Indexierung einer Seite ist die Grundvoraussetzung, damit diese als Ergebnis für eine Suchanfrage angezeigt werden kann. Deshalb ist es von entscheidender Bedeutung, ob eine Seite von Google indexiert wurde – oder eben nicht.
Bis Ende Januar 2022 konnte die Indexierung nur für jeweils eine einzelne Adresse überprüft werden. Die Methoden dafür waren neben der “URL Inspection” in der kostenlosen Google Search Console (auf Deutsch: URL-Prüfung) die Abfrage der Seite direkt bei Google, beispielsweie über den site:-Suchoperator. Hinter dem Doppelpunkt wurde dazu die gesuchte Adresse angegeben, also z. B. site:https://www.getindexed.io.
Mit dem Indexierungsbericht in der Google Search Console gibt es zudem eine weitere Möglichkeit, den Indexierungsstatus zu überprüfen. Seiten, die in den verschiedenen Berichten zu „nicht indexiert“ aufgeführt sind, sind entsprechend auch nicht indexiert. Besonders die Berichte „gecrawlt – zurzeit nicht indexiert“ und „gefunden – zurzeit nicht indexiert“ sind einen kritischen Blick wert.
Allerdings stehen in den GSC-Berichten nur maximal 1.000 Beispiel-Adressen zur Verfügung, und die gerade zu prüfende Adresse ist womöglich nicht Teil der Liste. Hier hilft die URL Inspection, oder die URL Inspection API. Während erstere nur für eine einzelne Seite die Prüfung erlaubt, ist es dank der URL Inspection API möglich, die Indexierung von mehreren Seiten auf einmal abzufragen.
Was die API kann und wofür du sie einsetzen kannst, erfährst du in diesem Artikel.
Inhaltsverzeichnis
- 1 Das Wichtigste zur URL-Inspection API in aller Kürze
- 2 Was ist die URL Inspection API?
- 3 Welche Daten liefert die URL Inspection API?
- 4 Wie kann die URL Inspection API abgefragt werden?
- 5 Wobei hilft die URL Inspection API?
- 6 Welche Unterschiede gibt es zwischen der API und der URL Überprüfung in der Google Search Console?
Das Wichtigste zur URL-Inspection API in aller Kürze
- Die URL Inspection (Deutsch: URL-Prüfung) erlaubt die Abfrage von Google-(Websearch-)Daten zu einzelnen Webseiten
- Die URL Prüfung steht für Einzelseiten in der Google Search Console, sowie für mehrere Seiten zeitgleich über die URL Inspection API zur Verfügung
- Mit dem Tool lässt sich herausfinden, ob und wann eine Seite zuletzt von Googles Crawlern (“Googlebot”) besucht wurde
- Während über die URL Inspection in der Google Search Console einzelne Adressen abgefragt werden können, kann über die URL Inspection API die Abfrage mehrerer Adressen zeitgleich erfolgen
- Die URL Inspection API wird kostenlos von Google angeboten
- Für die API (sowie die Abfrage in der Google Search Console) gibt es Quotas pro Tag, also definierte Maximalwerte
- Das Tool ist besonders für technische SEO und für große Websites mit mehreren 10.000 Webadressen interessant
Was ist die URL Inspection API?
Am 31. Januar 2022 hat Google die URL Inspection API vorgestellt. Die kostenfreie Schnittstelle erlaubt es, für mehrere Adressen auf einmal Informationen aus den Google-Systemen abzufragen. Im Kern hilft die API dabei herauszufinden, ob eine Seite von Google indexiert wurde.
Bisher war das über die Google Search Console für einzelne Adressen bereits möglich. Dank der kostenlosen Inspection API ist das jetzt für deutlich mehr Adressen (gleichzeitig) möglich. Die aktuellen Limits sind von Google wie folgt definiert worden:
- Bis zu 2.000 Abfragen für eine Google Search Console Property pro Tag
- Bis zu 600 Anfragen pro Minute
Doch was ist mit Google Search Console Property gemeint? Damit wird eine einzelne in der Google Search Console bestätigte Adressstruktur oder Domain beschrieben. Ein Beispiel:
- https://www.getindexed.io/
- http://www.getindexed.io/ (http statt https)
sind zwei separate Properties in der Google Search Console. Die oben genannten Maximalwerte (oder auch Quota) gelten für die jeweiligen Properties separat.
Dazu gibt es noch ein Quota für jeden “Schlüssel”, über den Anfragen gestellt werden. Die Maximalwerte für den Schlüssel können von verschiedenen APIs genutzt werden, also z. B. der PageSpeed API oder Search Analytics API. Mehr zu den aktuellen Quotas kannst du unter https://developers.google.com/webmaster-tools/limits#url-inspection nachlesen.
Doch was bedeutet das jetzt konkret? Für jede von dir in der Google Search Console bestätigten und auf der Website aktiv verwendeten Adressstruktur kannst du pro Tag 2.000 Anfragen stellen. Im Fall von getIndexed bedeutet das, dass jeweils bis zu 2.000 Anfragen für Adressen beginnend mit
- https://www.getindexed.io/
- https://www.getindexed.io/de/
- https://www.getindexed.io/de/knowledge-hub/
stattfinden können. Mit anderen Worten: Pro Tag können bei der gezeigten Struktur bis zu 6.000 Adressen innerhalb dieser Beispiel-Adressstrukturen direkt von Google abgefragt werden. Du kannst also von Google alle aktuell verfügbaren Daten zu den einzelnen Adressen abfragen. Das leitet perfekt über zum nächsten Abschnitt.
Doch noch kurz ein Lesetipp: hier erfährst du mehr über das perfekte Setup deiner Website in der Google Search Console.
Welche Daten liefert die URL Inspection API?
Ob du die “URL-Inspection” in der Google Search Console, oder eben die API nutzt: Die dir von Google zur Verfügung gestellten Daten sind identisch. Allerdings kannst du über die Google Search Console selbst immer nur eine Adresse abfragen, und über die API deutlich mehr.
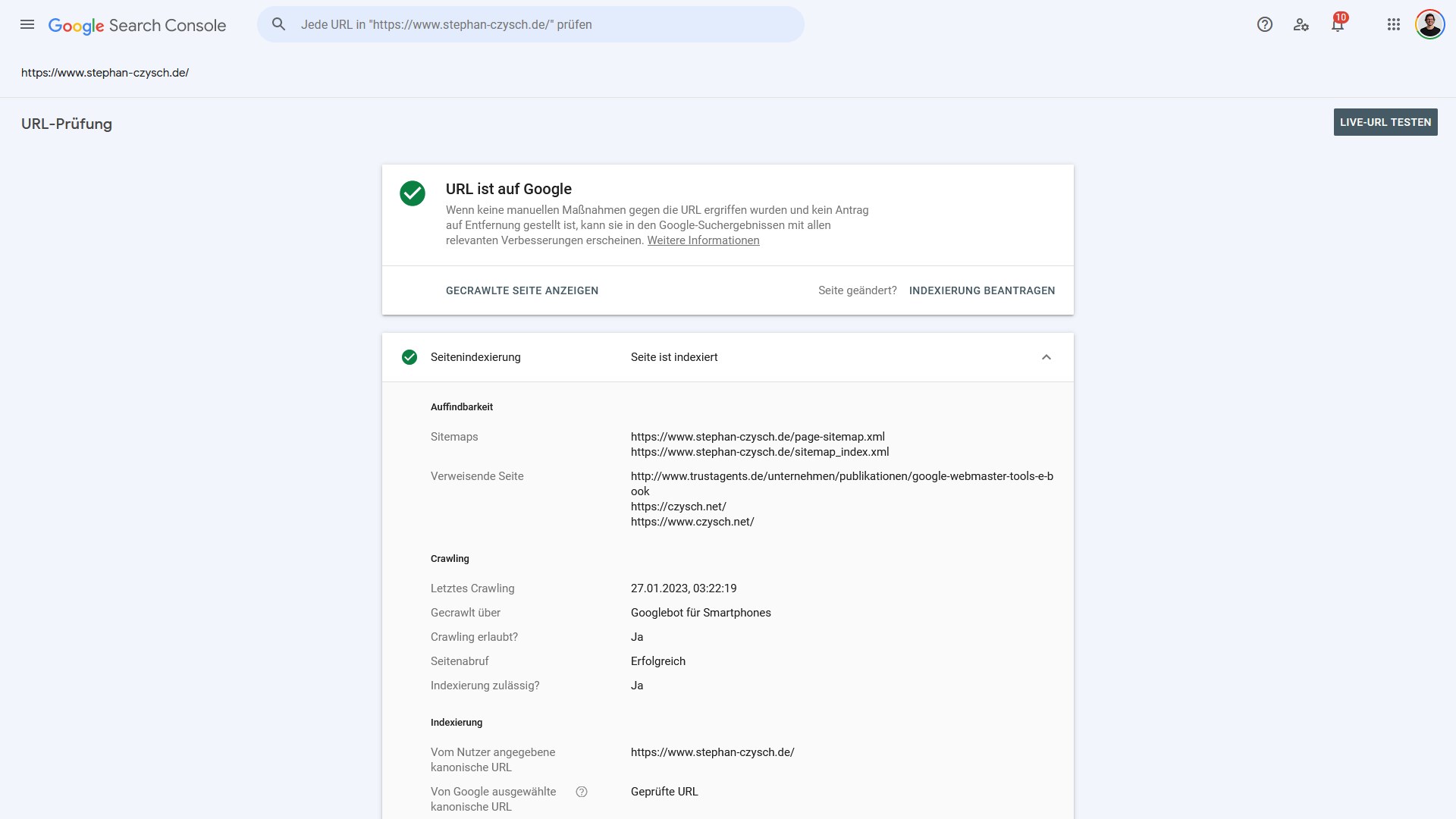
Der Indexierungsstatus ist direkt oben zu sehen. Dieser kann folgende Werte haben:
- Seite ist indexiert („URL ist auf Google“)
- Seite ist nicht indexiert
Woran eine “Nicht-Indexierung” liegen kann, lässt sich über die einzelnen unter “Seitenindexierung” angezeigten Informationen nachvollziehen.
Über die URL Inspection API werden exakt dieselben Daten geliefert, nur mit etwas anderen Bezeichnungen – und eben für mehrere Seiten auf einmal.

Google unterteilt die Daten bewusst in drei Kategorien:
- Auffindbarkeit
- Crawling
- Indexierung
Das sind die Schritte, die für jede erfolgreiche Indexierung, also die Verfügbarmachung einer Seite in den Suchergebnissen, notwendig sind.
Auffindbarkeit
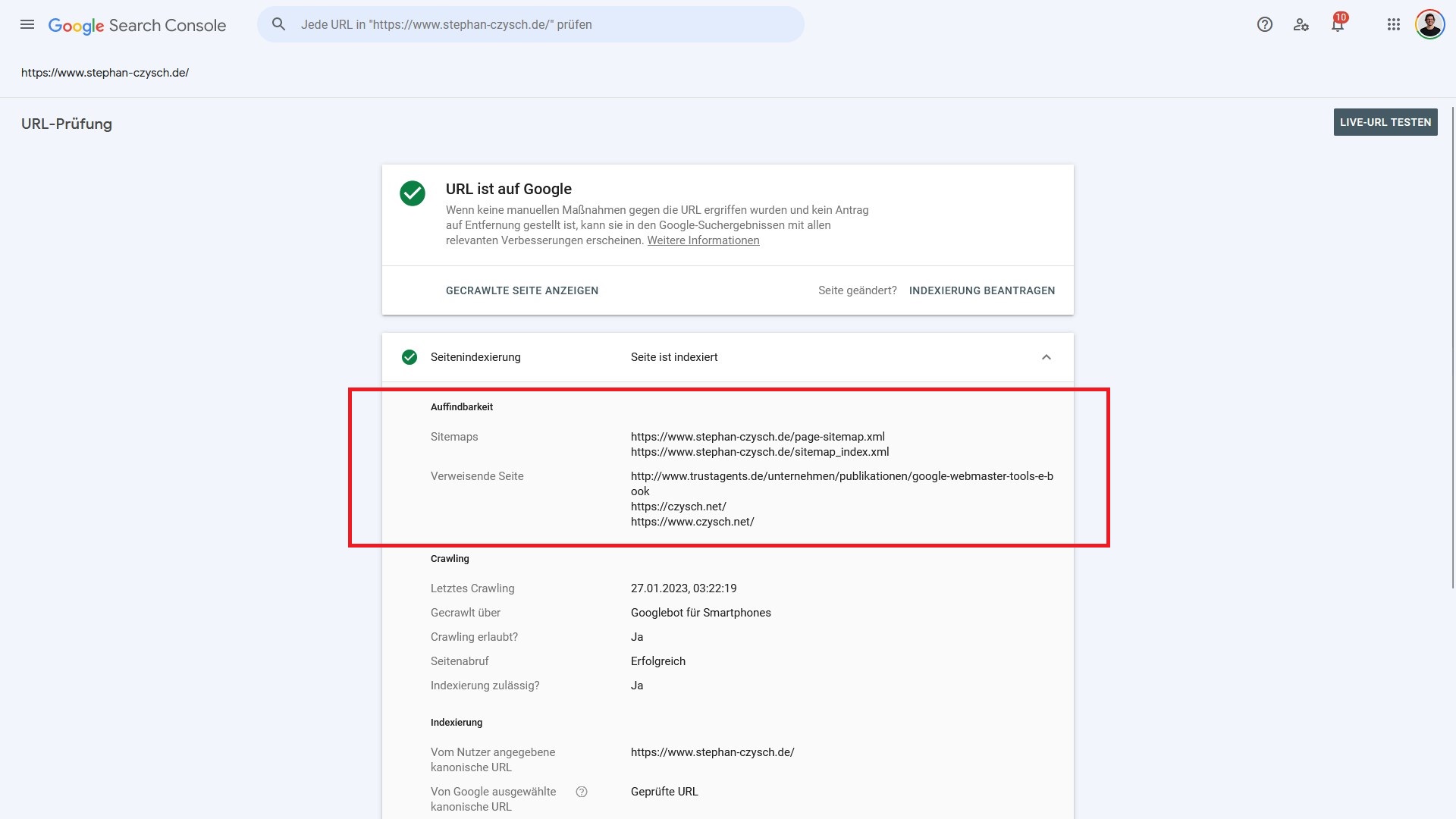
Worum gehts? Google und andere Suchmaschinen können nur auf Adressen zugreifen, die der Suchmaschine bekannt sind. In der URL Inspection nennt Google zwei mögliche Quellen, die zur Auffindbarkeit geführt haben können: Sitemaps und verweisende Seite(n).
Sitemaps: Sitemaps, in der Regel handelt es sich hierbei um Sitemaps im XML-Format, sind für die Suchmaschinenoptimierung weiterhin wichtig. Diese Dateien listen Adressen des Webauftritts auf und sorgen dadurch dafür, dass Suchmaschinen überhaupt Adressen kennen.
Damit das natürlich funktioniert, muss die Suchmaschine darüber informiert werden, dass es eine Sitemap gibt und wo sie zu finden ist. Für Google passiert das idealerweise über die Google Search Console unter “Sitemaps”, sowie über einen Verweis auf die Sitemap in der robots.txt-Datei.
Verweisende Seiten: Links, oder auch Verweise, sind ein integraler Bestandteil des Webs. Auch über Verweise von bereits bekannten Seiten können Suchmaschinen (neue) Adressen finden.
Nicht immer sind im Bericht verweisende Seiten, oder sogar Sitemaps genannt. Und wenn, dann handelt es sich immer um Beispiele, und keine vollständige Information.
Sollten diese beiden Datenfelder der URL Inspection leer sein, dann ist es dennoch möglich, dass die analysierte Seite dennoch über einen Verweis oder eine nicht genannte Sitemap “bekannt” und damit “auffindbar” wurde. Alternativ können Seiten auch direkt an Google übermittelt werden, beispielsweise über die URL Inspection oder die Google Indexing API.
Crawling
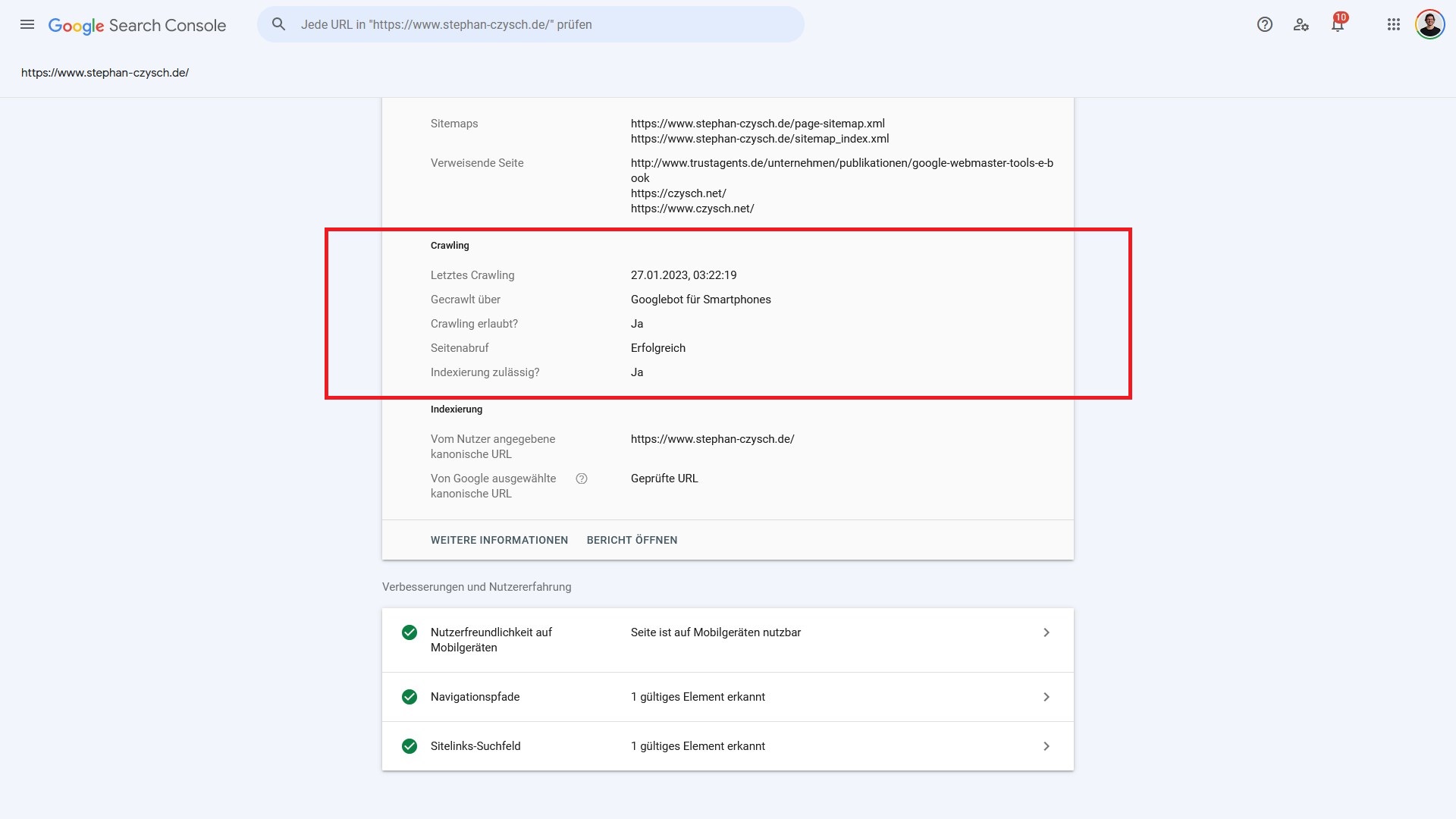
Worum geht’s? Mit Crawling wird der “Leseprozess” einer Webseite beschrieben. Damit eine Seite gelesen werden kann, sind ein paar Vorbedingungen notwendig. Denn zunächst muss das Crawling einer Adresse erlaubt sein, und dann muss die Adresse auch erfolgreich aufgerufen werden können.
Ob eine Seite gelesen werden darf, wird über die sogenannte robots.txt gesteuert. Über diese Datei ist es möglich, den Zugriff auf Seiten- oder Seitenbereich via Angabe Disallow: /adresse zu steuern.
Wenn kein Disallow für eine bekannte Adresse vorliegt, dann wird diese angesteuert. In diesem Schritt ist es möglich, dass die Suchmaschine auf eine nicht (mehr) vorhandene, oder eine umgezogene Adresse zugreift. Das sind die sogenannten HTTP-Statuscodes.
Im Falle einer nicht gefundenen Seite wird die Zugriffsanfrage mit 4xx, meistens 404 (not found) oder 410 (gone) beantwortet. Für Inhalte, deren Adresse sich geändert hat, ist ein HTTP-Statuscode von 301 (dauerhaft umgezogen) oder 302 (temporär umgezogen) die Antwort des Webservers.
Letztes Crawling: Unter diesem Datenfeld ist der Tag und die Uhrzeit des letzten Zugriffs(versuchs) auf die Adresse gemeint.
Gecrawlt über: Google crawlt das Netz vor allem als “Mobilgerät”. Den von Google verwendeten User-Agent, also die Nutzerkennung, kannst du hier einsehen. Alle von Google genutzten sogenannten User-Agents sind in dieser Google-Hilfe aufgelistet.
Seitenabruf erfolgreich: Hier geht es um den Statuscode, also ob die Adresse aufgerufen werden konnte oder nicht. Gibt es das Dokument, dann liefert der Webserver den Statuscode 200 (OK), samt des eigentlichen Seiteninhalts aus.
Indexierung zulässig: Google hat also erfolgreich auf die analysierte Adresse zugreifen können. Jetzt geht es darum, um die Seite auch grundsätzlich zur Indexierung freigegeben wurde. Hier kommen die sogenannten Robots-Tags ins Spiel. Sagt entweder Meta Robots oder X-Robots hier “Noindex”, dann ist die Indexierung nicht zulässig. Das ist gleichbedeutende mit einem “Abbruch” des Indexierungsprozesses.
Indexierung
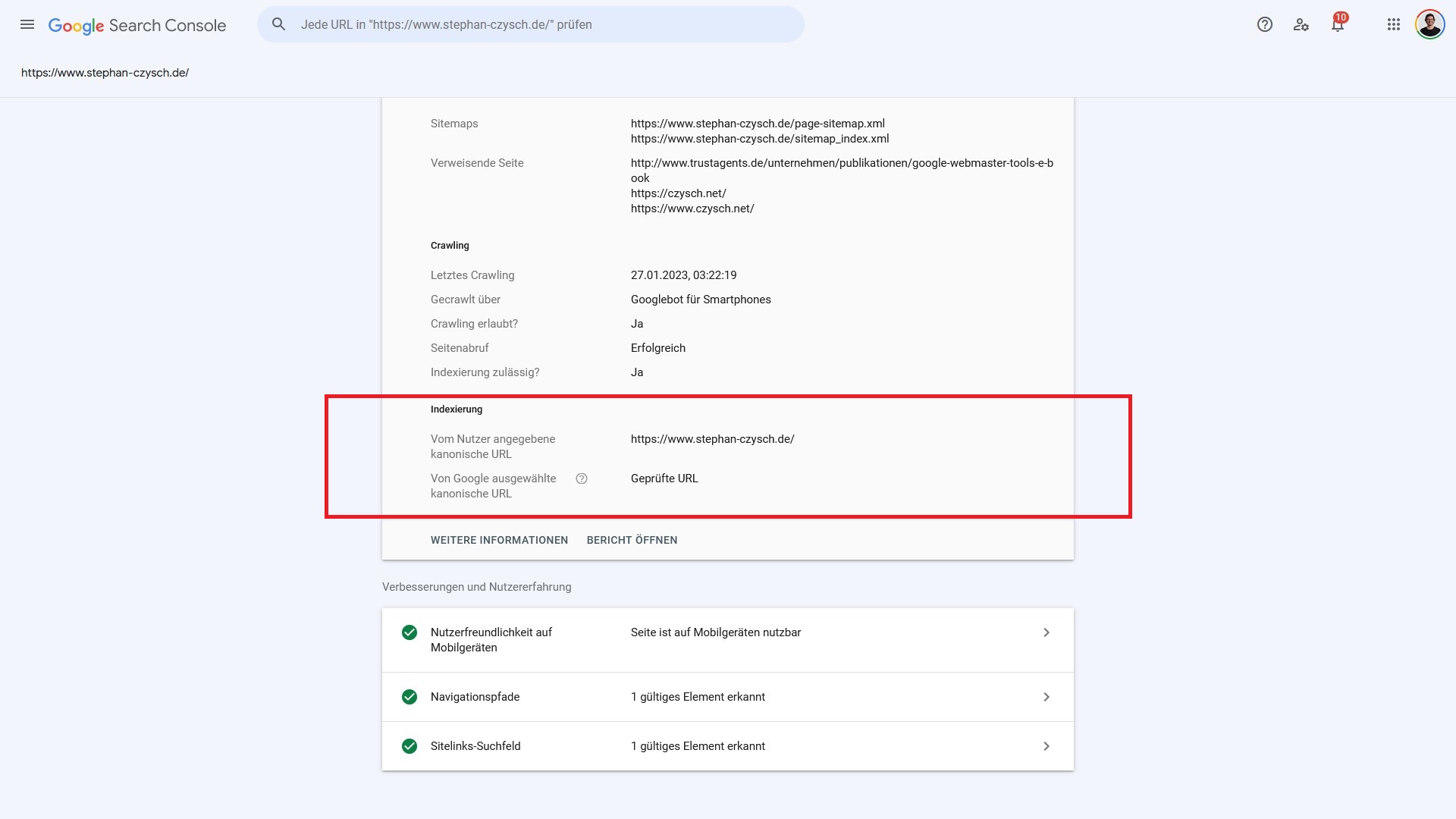
Worum geht’s? Wenn die Vorbedingungen erfolgreich waren, dann geht es jetzt darum, ob die analysierte Seite in den Google-Index hinzugefügt wird.
Vom Nutzer angegebene kanonische URL: Wenn das sogenannte Canonical-Tag bzw. die sogenannte Canonical-URL definiert wurde, dann gibt Google diese Adresse an dieser Stelle aus.
Das Canonical-Tag ist dafür gedacht, eine Adresse als “Hauptadresse” (“Canonical-URL”) zu kennzeichnen, wenn derselbe Inhalt unter mehreren Adressen verfügbar ist. Das ist der sogenannte “Duplicate Content”.
Von Google ausgewählte kanonische URL: Die vom Nutzer definierte Canonical-URL kann von Google akzeptiert werden, muss allerdings nicht. Hat sich Google für eine andere Adresse als kanonisch entschieden, dann wird diese Adresse an dieser Stelle ausgegeben. Ansonsten steht hier “Geprüfte URL”. Damit ist gemeint, dass die im URL-Inspection Tool überprüfte Adresse von Google als kanonische Adresse angesehen wird.
Weitere Daten
Für indexierte URLs gibt Google zudem weitere Daten aus. So überprüft Google im Laufe des Indexierungsprozesses, ob eine Seite problemlos auf Mobilgeräten angezeigt werden kann, und ob strukturierte Daten zum Einsatz kommen.
Wie kann die URL Inspection API abgefragt werden?
Es gibt eine ganze Reihe von fertigen Lösungen, über die die URL Inspection API abgefragt werden kann. So bieten unter anderem der Screaming Frog, Valentin.app eine Abfrage der API an.
Technisch versierte Personen können über https://developers.google.com/webmaster-tools/v1/urlInspection.index/inspect die API selbst ausprobieren, oder anhand der Anleitung eigene Methoden zur Abfrage der URL Inspection programmieren. Mit dem Tool von Valentin Pletzer kann die Ad-Hoc Abfrage von bis zu 2.000 URLs kostenfrei durchgeführt werden.
Wobei hilft die URL Inspection API?
Die API hilft technischen SEOs dabei, den Indexierungsstatus mehrerer Seiten auf einmal bei Google abzufragen. Dadurch kann nicht nur überprüft werden, ob die analysierten Seiten indexiert wurden, sondern es werden auch Hinweise geliefert, warum eine Seite nicht (mehr) im Google Index vorliegt. In der Folge kann diese Seite nicht in den Suchergebnissen auftauchen
Eine solche Analyse des Indexierungsstatus ist besonders bei großen Websites relevant. Von großen Websites spreche ich, wenn eine Seite mehrere 10.000 Adressen hat.
Für viele Webmaster ist dabei besonders relevant, wann Google eine Seite zuletzt gecrawlt hat, und ob die vom Nutzer hinterlegte Canonical-URL übernommen wurde.
Welche Unterschiede gibt es zwischen der API und der URL Überprüfung in der Google Search Console?
Im Kern liefert sowohl die URL Inspection in der Google Search Console, sowie die URL Inspection API dieselben Daten. Doch es gibt Funktionen, die nur in der Google Search Console vorliegen.
Die exklusiv in der Search Console vorliegenden Möglichkeiten der URL-Inspection sind:
- Die Möglichkeit, den von Google analysierten Quelltext zu sehen
- Ein (emuliertes) optisches Abbild der Seite anzuzeigen
- Die HTTP-Headerantwort einzusehen
- Eine Indexierung der Seite zu beantragen
Besonders die letztgenannte Möglichkeit ist für viel Webmaster entscheidend. Denn abseits der Google Indexing API, die in getIndexed integriert ist, gibt es keine Möglichkeit, eine Seite zur erneuten oder erstmaligen Indexierung bei Google zu melden.
In der Summe bedeutet das, dass im Zusammenspiel der URL Inspection in der Google Search Console und der dazugehörigen API die für technische SEOs wichtigen Daten liegen. Erst im Zusammenspiel kann das gesamte Potenzial genutzt werden.