Egal, in welche Google Search Console man schaut: Es gibt einen hohen Anteil an Seiten, die Google zwar kennt, aber nicht indexiert hat. Mit Blick auf die Nicht-Indexierung sind besonders die beiden Gruppierungen:
relevant.
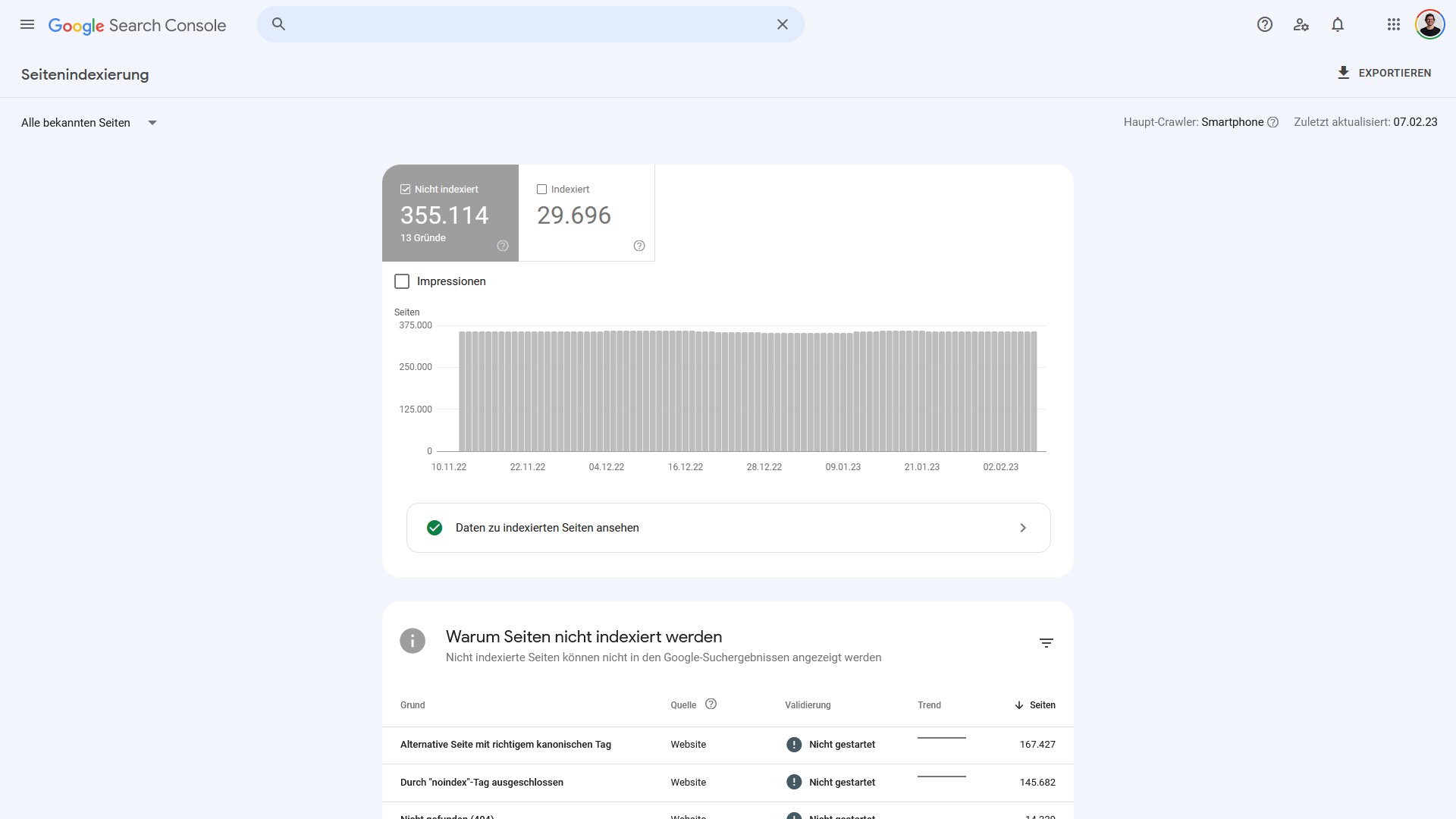
Was diese beiden Gruppen bedeuten, und was „Gegenmaßnahmen“ sind, ist im verlinkten Artikel beschrieben. In diesem Artikel hier geht es darum, was eigentlich ein guter Indexierungsstatus ist.
Wie viele und welche Seiten sollen überhaupt indexiert sein?
Grundsätzlich kann das gesamte URL-Inventar einer Website in die folgenden Gruppen unterteilt werden:
- URLs, die (nicht) gecrawlt werden müssen
- URLs, die (nicht) indexiert werden müssen
Adressen, die Google aus Sicht des Webmasters gar nicht crawlen muss, sind in der Folge auch nicht für die Indexierung relevant. Die können in der Betrachtung des „richtigen“ Indexierungsstatus von vornherein ignoriert werden. Welche Seiten(typen) in den „muss nicht gecrawlt Topf“ gehören, ist von Website zu Website unterschiedlich. Beispiele können z.B. die interne Suche sein.
Aus Sicht einer Suchmaschine sind eigentlich (fast) alle nicht zur Indexierung vorgesehen Adressen aus Crawling-Sicht irrelevant. Denn das Ziel einer Suchmaschine wie Google ist es, Seiten zu analysieren, die Suchanfragen beantworten können. Oder anders formuliert: Die „perfekte“ Website aus Sicht eines Crawlers besteht ausschließlich aus inhaltlich hochwertigen, indexierbaren Seiten.
In der Regel machen crawlbare Adressen den Großteil einer Website aus. Diese Adressen sind entweder für die Website-Struktur relevant, machen also wichtige Seiten erreichbar, oder tragen selbst ein relevantes Keyword und sind damit ein potenzieller Einstieg für Suchende.
Innerhalb der crawlbaren Adressen gibt es regelmäßig Seiten, die:
- Per Canonical-Tag auf eine andere Seite verweisen
- Mittels Noindex von der Indexierung ausgeschlossen sind
Diese Adressen werden zwar gecrawlt, sind dann aber (bewusst) vom Webmaster von der Indexierung ausgeschlossen worden.
Der Indexierungsstatus in der Google Search Console ist erstmal nur ein numerischer Wert und sagt wenig über die Qualität der indexierten Seiten aus. Auch ist nur bedingt einsehbar, welche Adressen genau indexiert sind.
Die zentrale Frage mit Blick auf die Indexierung ist immer, wie viele Seiten (geschätzt) indexiert sein sollten. Mit einem Crawler wie dem Screaming Frog kann das (intern verlinkte) URL-Inventar sowie die davon indexierbare Seitenanzahl erhoben werden. Das ist schonmal ein erster Richtwert, wie viele Seiten tendenziell indexiert sein sollten.
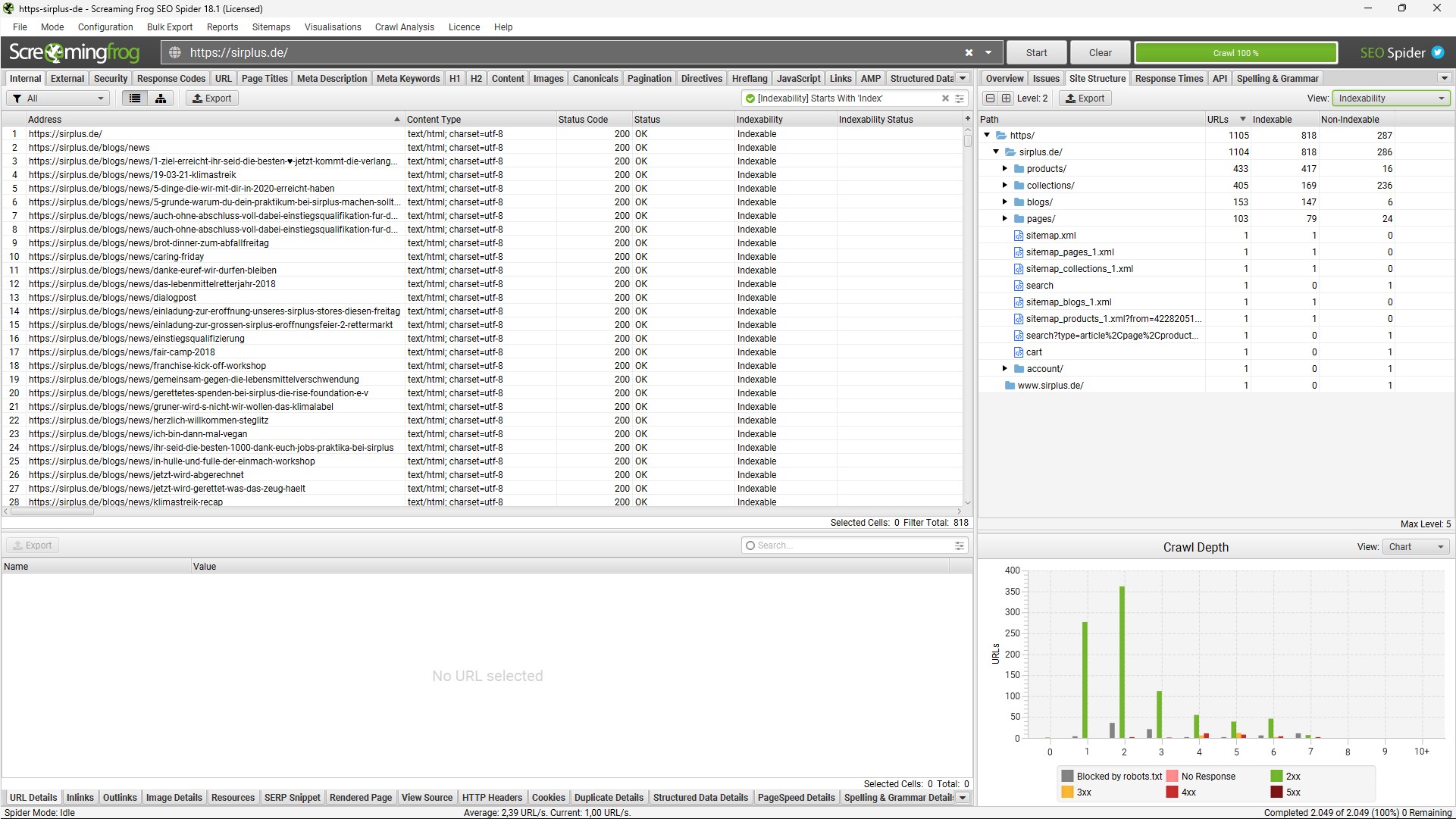
Bei der im Screenshot zu sehenden Seite sind 818 indexierbare Adressen gefunden worden. Beim Blick in die Google Search Console werden allerdings 2.390 indexierte Seiten gemeldet.
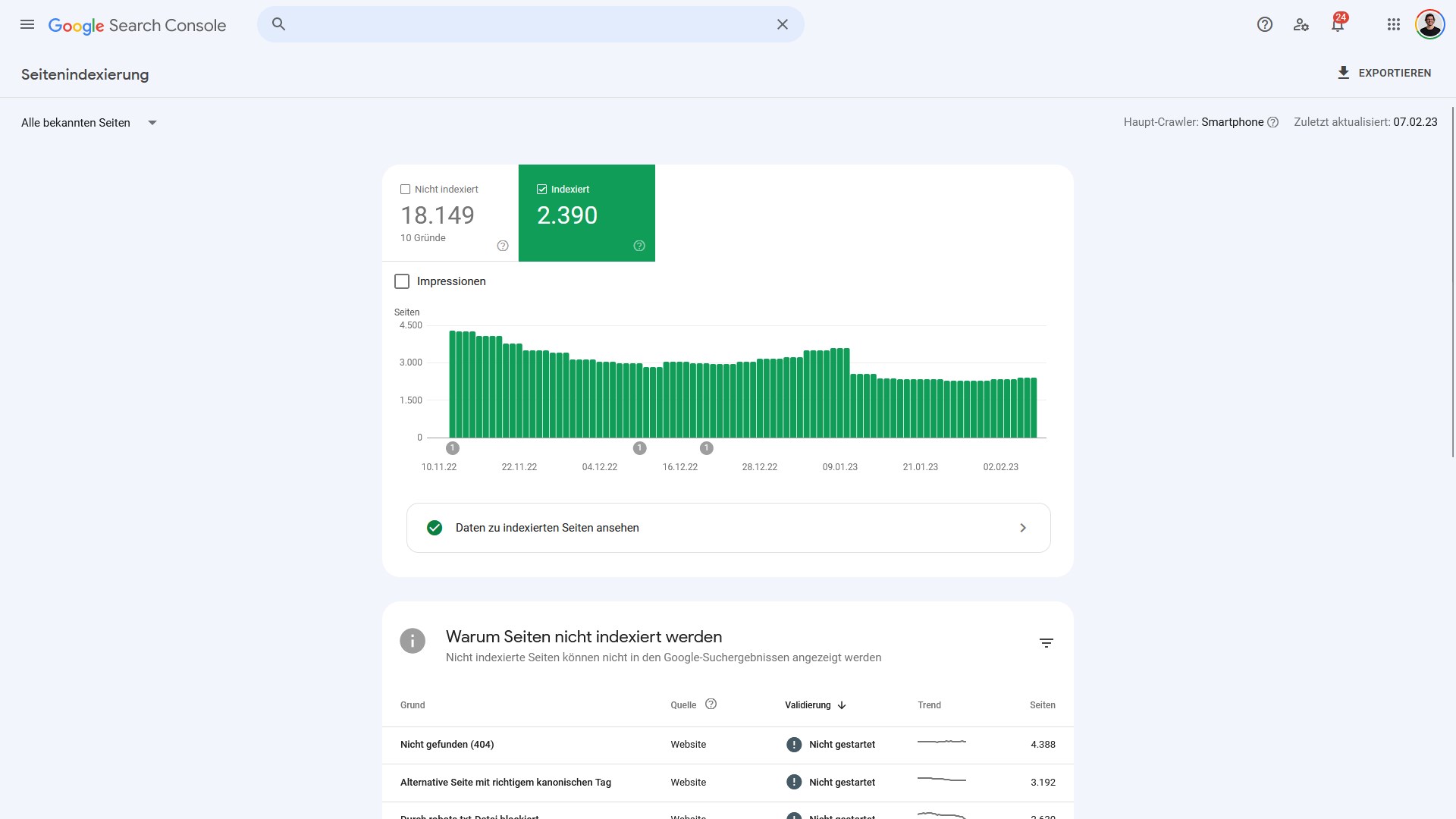
Im Fall dieser Domain sind mehr Seiten indexiert als im Crawl gefunden wurden. Die Gründe dafür können vielfältig sein, hier ein paar Möglichkeiten:
- Seitenbereiche waren für den Screaming Frog nicht erreichbar, beispielsweise weil kein interner Link zu diesen Adressen zeigt
- Canonical-Tags wurden von Google nicht befolgt
Merke: Der Indexierungsstatus in der Google Search Console ist erstmal nur eine Zahl und muss mit Kontext „gefüllt“ werden.
In der Google Search Console können pro Property bis zu 1.000 indexierte Seiten eingesehen werden. Deshalb ist das richtige Setup der Google Search Console so wichtig.
Darüber hinaus kann über die URL Inspection (API) der aktuelle Indexierungsstatus einer Seite abgefragt werden. Neben diesen beiden Klassikern gibt es noch eine dritte Möglichkeit: die XML-Sitemaps. Denn der Indexierungsbericht in der Search Console wird nach „alle bekannten“ und „alle eingereichten URLs“ unterteilt.
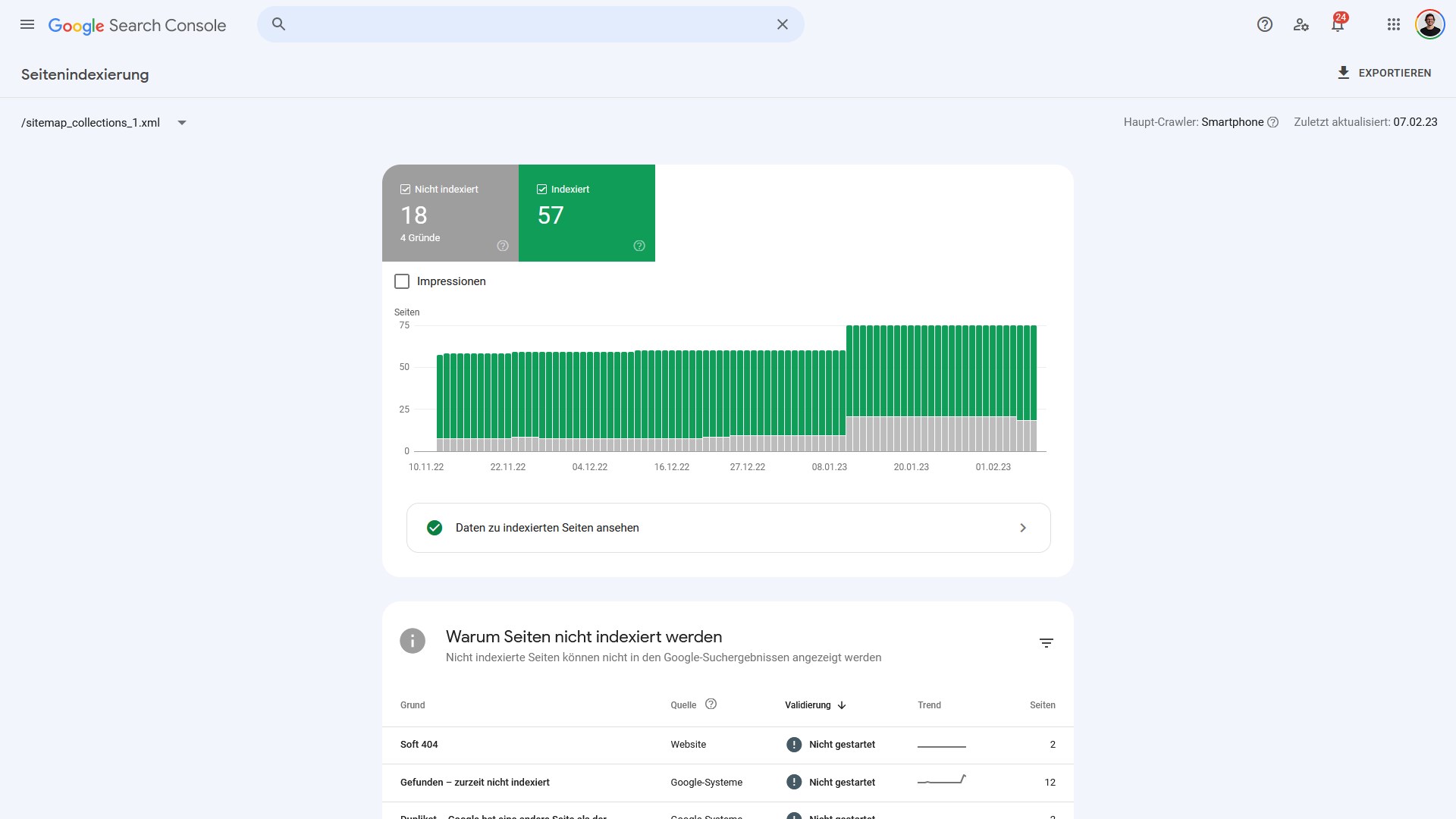
Mit Blick auf die Beispielwebsite gibt es auf den ersten Blick ein gemischtes Bild. Es sind sowohl mehr Seiten indexiert als gedacht, aber manche eingereichten Seiten wurden nicht indexiert.
Die zentrale Frage: Sind relevante Seiten nicht indexiert?
Die entscheidende Frage mit dem Blick auf den Indexierungsstatus ist immer die, ob irrelevante Seiten indexiert wurden, und relevante Seiten nicht indexiert sind. Die Google Search Console liefert immer nur eine Zahl – für den Kontext bist du verantwortlich.
Es ist also an dir, die Spreu vom Weizen zu trennen. Denn immer dann, wenn für dich aus (potenzieller) organischer Zugriffssicht relevante Seiten nicht indexiert sind, dann hast du ein Problem.
Wenn das auf Adressen deiner Website zutrifft, dann kann dir getIndexed vermutlich dabei helfen, eine Indexierung zu erreichen.
Schreibe einen Kommentar