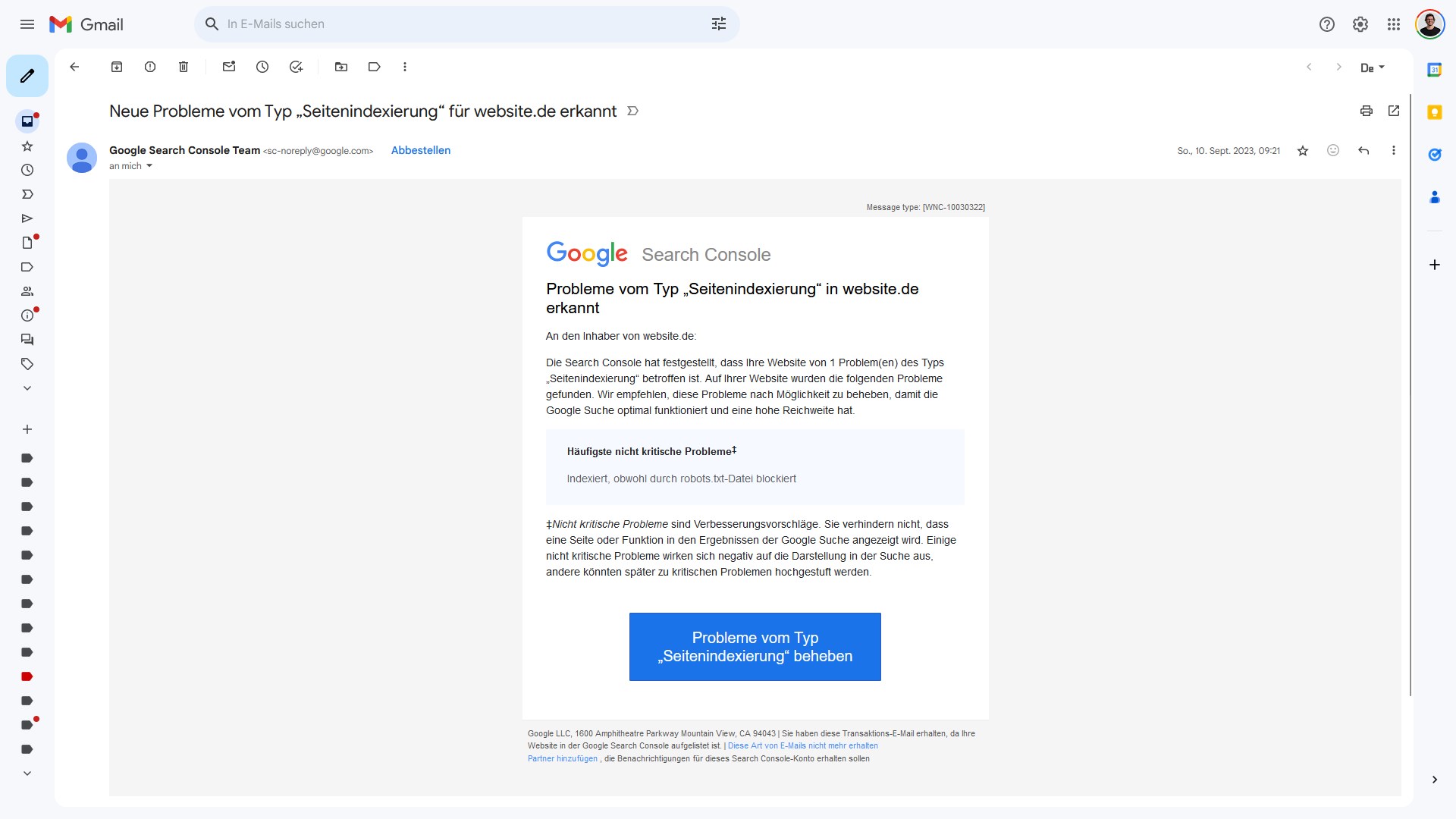
Ohne Indexierung ist kein Ranking bei Google möglich. Wenn Probleme mit der Indexierung vorliegen, dann informiert Google darüber sowohl in der Google Search Console innerhalb des Indexierungsberichts, als auch per E-Mail. Der Betreff der E-Mail lautet Neue Probleme vom Typ Seitenindexierung. Doch was bedeutet das? Und was muss unternommen werden?
Diese E-Mail kann zwei unterschiedliche Betreffzeilen haben:
- Neue Probleme vom Typ „Seitenindexierung“ in [website] erkannt
- Neue Probleme vom Typ „Seitenindexierung“ in den eingereichten URLs für [website] erkannt
Wie im Indexierungsbericht auch unterscheidet Google bei den Benachrichtigungen zwischen „alle bekannten URLs“ und „alle eingereichten URLs“:
- Eingereichte Seiten: Alle Webadressen, die über eine XML-Sitemap innerhalb der Google Search Console an Google gesendet werden.
- Bekannte Seiten: Alle Webadressen, die Google aus unterschiedlichen Quellen kennt.
Inhaltsverzeichnis
Was muss ich tun, wenn ich die Nachricht „Neue Probleme vom Typ Seitenindexierung“ erhalte?
Erstmal vorneweg: Die Nachricht informiert darüber, dass einzelne Webadressen nicht von Google indexiert wurden beziehungsweise indexiert werden konnten. Sie können also nicht in der Google-Suche erscheinen. Die Nachricht ist also zunächst nur ein Hinweis.
Mit der Nachricht informiert Google nur darüber, dass zu einer Fehlergruppe jetzt mehr Seiten zugeordnet werden. Es handelt sich also um bereits vorher vorhandene Fehlergruppen, aber weitere Seiten geben diesen Fehler aus.
Damit unterscheidet sich diese Nachricht von der sehr ähnlichen Benachrichtigung mit dem Betreff „Neue Gründe verhindern die Indexierung von Seiten„. In diesem Fall tritt eine Fehlergruppe erstmalig auf der Website auf.
Mehr URLs haben also ein spezielles Indexierungsroblem – muss ich handeln?
Ob tatsächlich ein Problem vorliegt, ist davon abhängig, ob die gemeldete(n) Seite(n) aus Sicht des Website-Inhabers indexiert sein sollte. Das bedeutet, dass auf der Adresse ein wichtiger Inhalt zu finden ist, für den die Website gefunden werden soll. Wenn (eher) unwichtige Adressen von Google gemeldet werden, dann liegt kein Problem vor.
Sprich, folgende Schritte müssen bei Erhalt der Nachricht oder der Analyse in der Google Search Console unternommen werden:
- Welche Adressen sind von Indexierungsproblemen betroffen?
- Liegt das von Google beschriebene weiterhin Problem vor? Dazu die Seite aufrufen
- Sind die betroffenen Adressen für den SEO-Erfolg wichtig?
- Ja: Weitere Analyse notwendig.
- Nein: Keine weiteren Schritte notwendig.
Noch ein genereller Tipp: Mit einem Tool wie httpstatus.io kannst du die Adresse nochmals von einer „neutralen Umgebung“ prüfen. Das Tool zeigt dir leicht verständlich den sogenannten HTTP Statuscode einer Seite an. Das ist vereinfacht gesagt die Information, ob eine angefragte Seite vorliegt oder nicht. Bekannt ist der Statuscode 404 für nicht vorhandene Seiten, oder 200 für erfolgreich abrufbare Adressen.
Die Grundlagen: Das sagt der Indexierungsbericht der Google Search Console
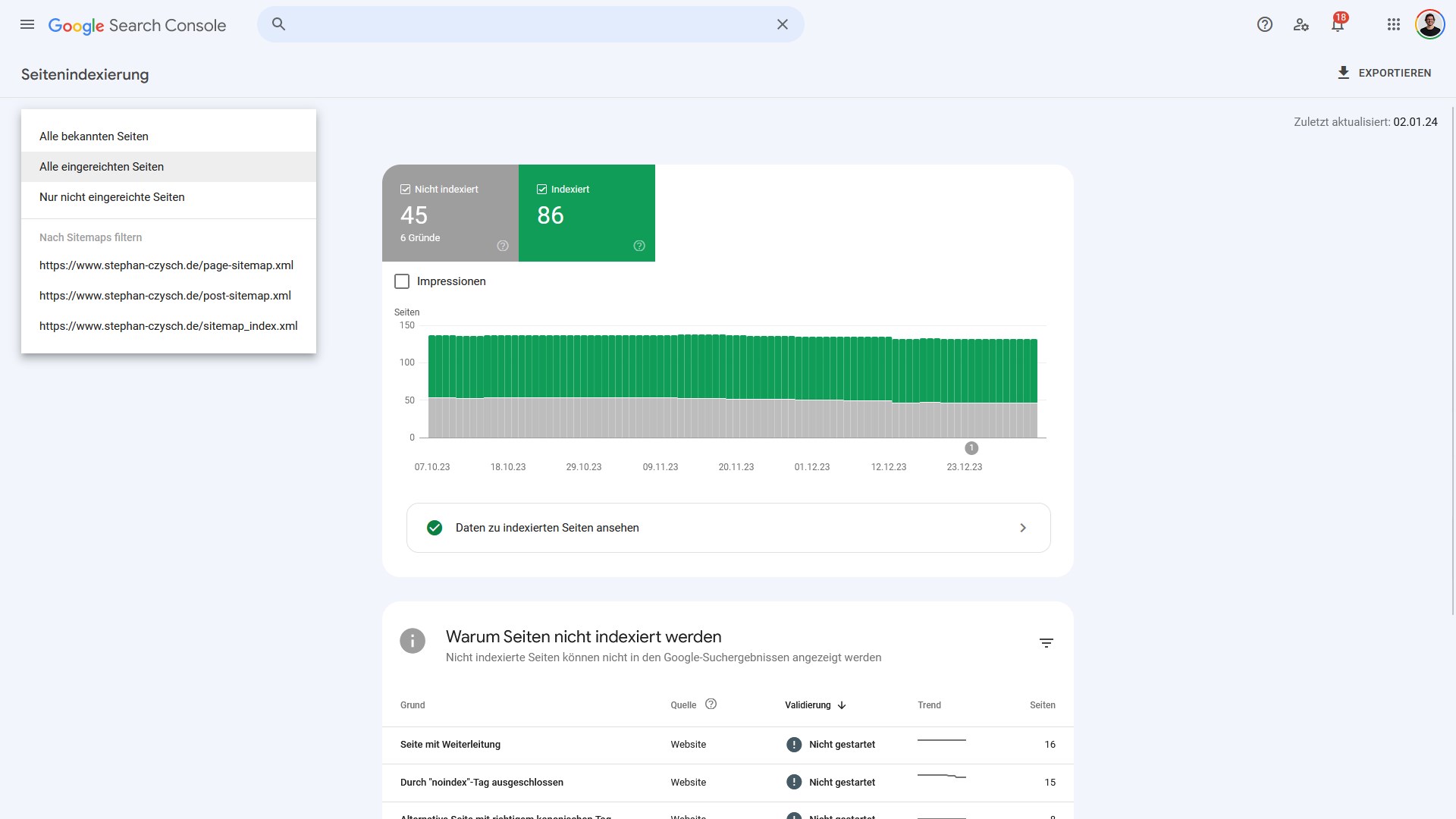
Mit der Google Search Console haben Webmaster die Möglichkeit, die „Seitenindexierung“ (oder auch Indexierungsstatus) einzelner Webseiten und der Website insgesamt zu überprüfen.
Während für die Überprüfung einzelner Seiten die URL Inspection (deutsch: URL Prüfung) genutzt werden kann, ist für den Indexierungsstatus der Website insgesamt der Bericht „Seiten“ unter dem Punkt „Indexierung“ die richtige Anlaufquelle. Die URL Inspection ist die blaue Schaltfläche auf dem Screenshot. Auch über die neben einzelnen Adressen angezeigte Lupe kann die URL-Prüfung aufgerufen werden.
Grundsätzlich müssen Seiten (URLs) die Prozesskette
- Auffindbarkeit: Google kennt die Adresse
- Crawling: Google konnte die Seite erfolgreich aufrufen
- Indexierung: Google darf die Seite indexieren
durchlaufen, um in den sogenannten Google Index zu kommen. Der Google Index ist die Sammlung aller von Google indexierten Seiten. Und nur diese können in den Suchergebnissen erscheinen.
Grundsätzlich unterteilt Google den Indexierungsbericht in die drei Bereiche:
- Indexiert
- Nicht indexiert („Warum Seiten nicht indexiert sind“)
- Darstellung von Seiten verbessern.
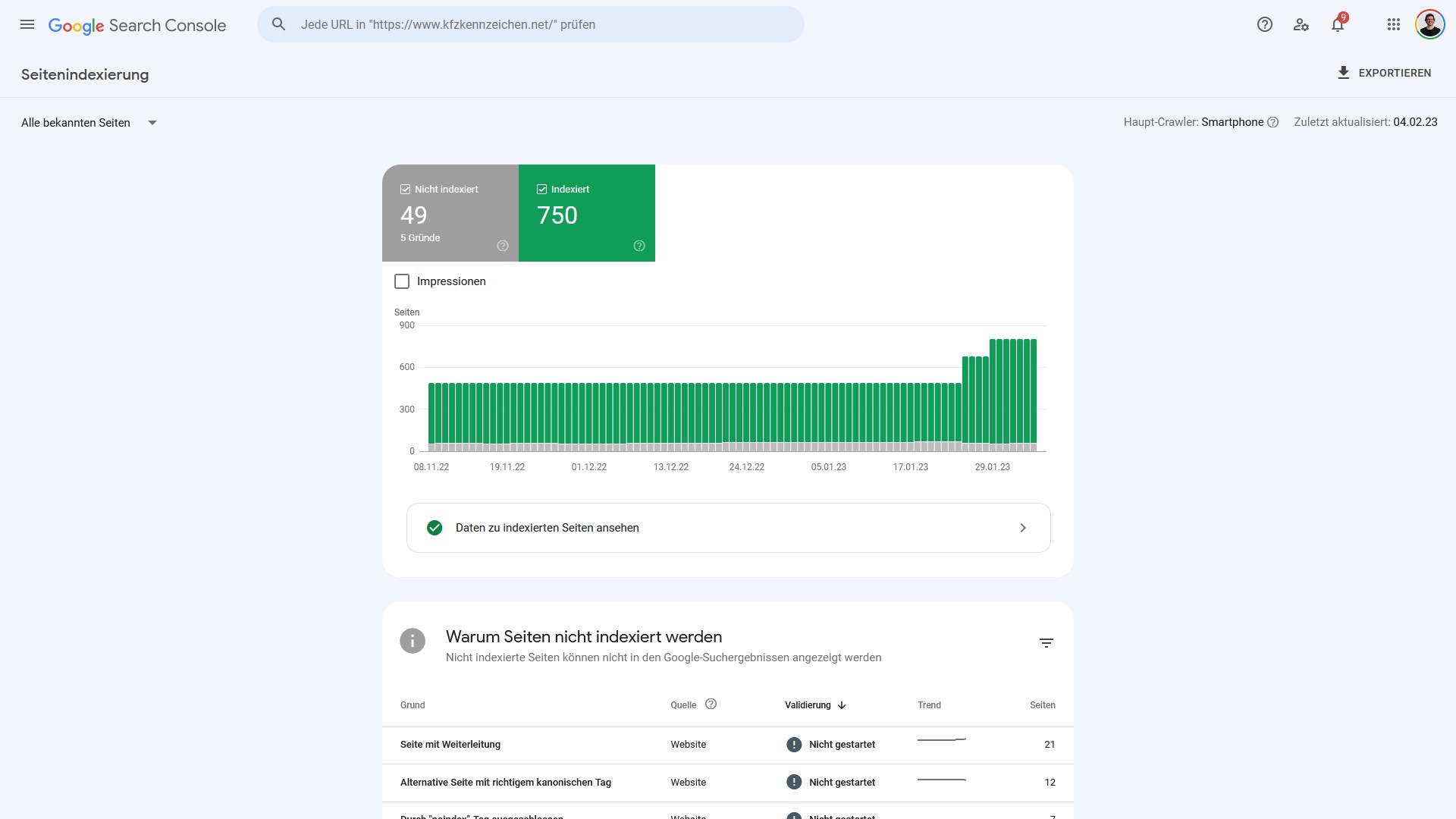
„Warum Seiten nicht indexiert sind“ ist der Bericht, der Hinweise über Indexierungsprobleme gibt. Google unterscheidet dabei nach vielen verschiedenen Gründen, die wir uns gleich im Detail anschauen. Die Gruppen sind zwischen Websites identisch, doch nicht alle treten bei jeder Website auf.
Dazu wird als Quelle für die Nicht-Indexierung zwischen „Google Systeme“ und „Website“ unterschieden.
- Website: Aufgrund von Anweisungen / Problemen auf der Website sind die Seiten nicht indexiert
- Google Systeme: Aufgrund der Entscheidung von Google wurden Seiten nicht indexiert
Probleme ergeben sich in der Regel durch die sogenannten HTTP-Statuscodes. Nur Seiten, die erfolgreich auf einen Seitenaufruf antworten (Statuscode 200), können von Google indexiert werden. Alle anderen Statuscodes führen zu einer Nicht-Indexierung von Seiten. Sprich eine Seite, die nicht vorhanden ist (Statuscode 404), wird von Google nicht indexiert. Doch auch durch technische Angaben wie Meta Robots oder Canonical-Tag können Seiten (bewusst) nicht indexiert werden.
Auf der Übersichtsseite siehst du, wie viele Seiten gerade zur jeweiligen Gruppe von „Warum Seiten nicht indexiert sind“ gehören:
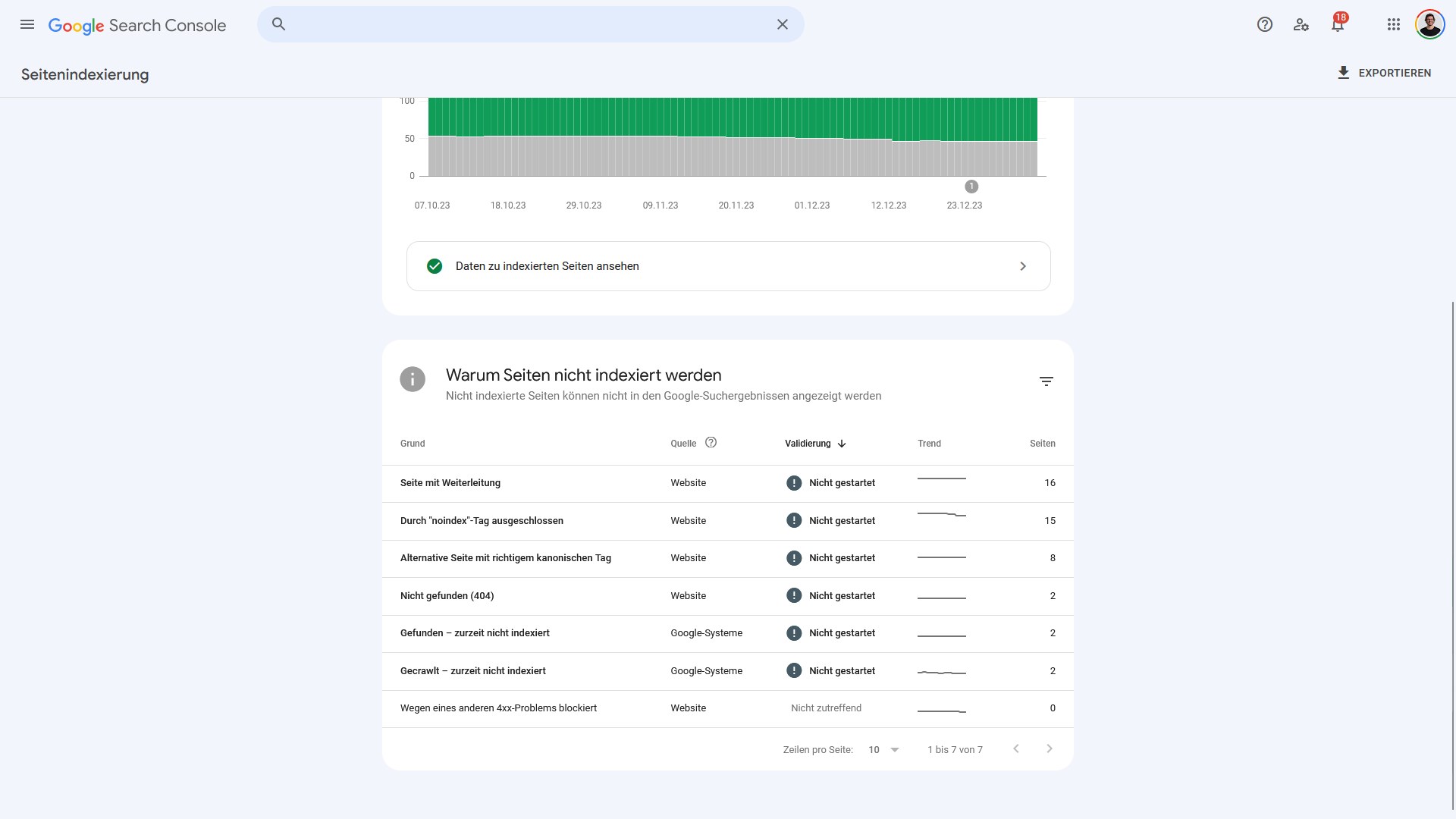
Die Trendlinie zeigt dir zudem, ob im zeitlichen Verlauf mehr oder weniger Seiten zur jeweiligen Gruppe zugeordnet werden.
Um die von einem Grund betroffenen Adressen zu sehen, musst du die jeweilige Fehlergruppe aufrufen. Im Fall der 16 von „Seite mit Weiterleitung“ betroffenen Adressen sieht die Detailansicht so aus:
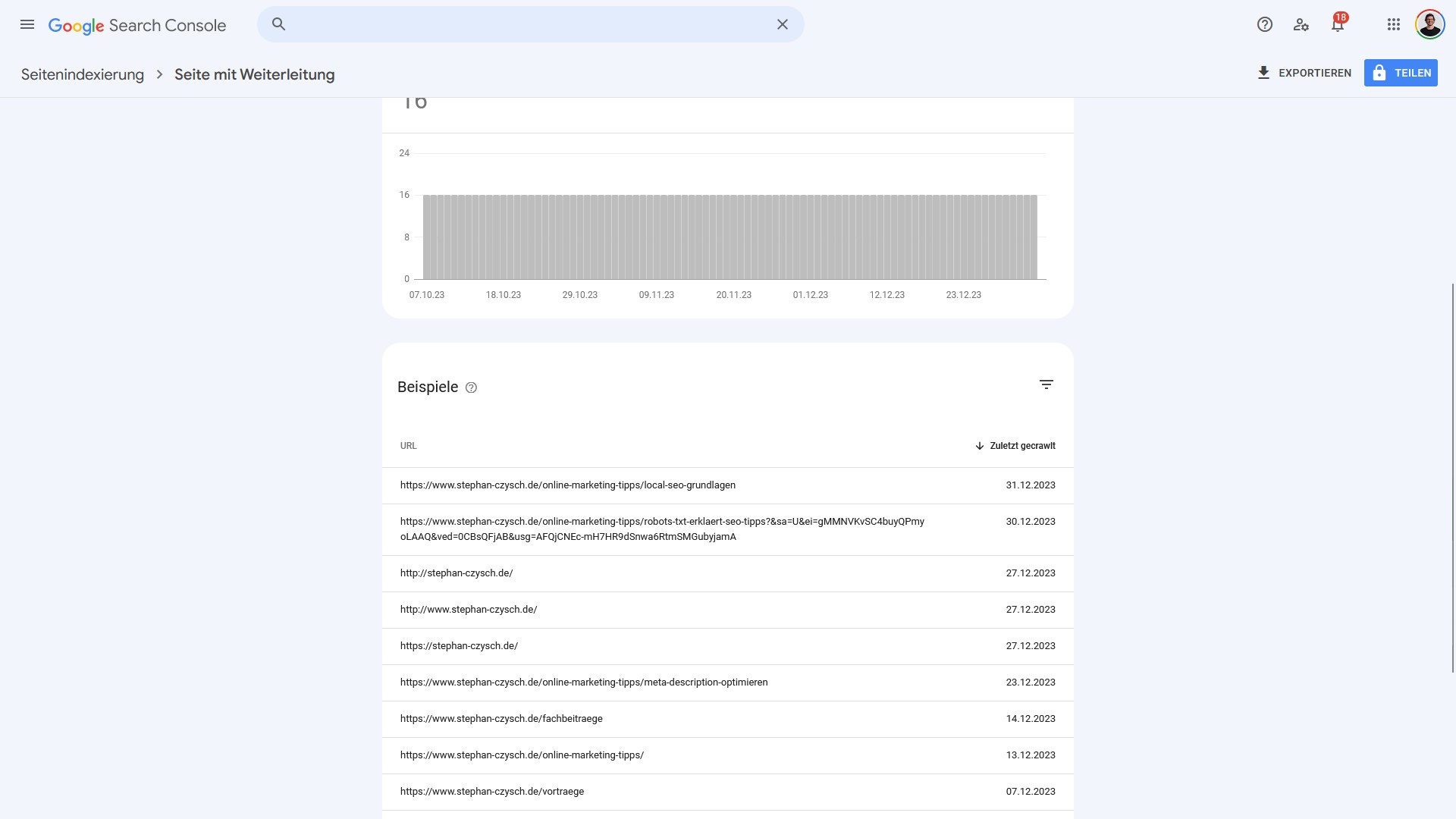
Was bedeutet das? Google meldet, dass die genannten Adressen auf andere Adressen weiterleiten. Das wird vor allem über die HTTP Statuscodes 301 und 302 bewerkstelligt. Die eigentliche Seite ist also nicht mehr vorhanden.
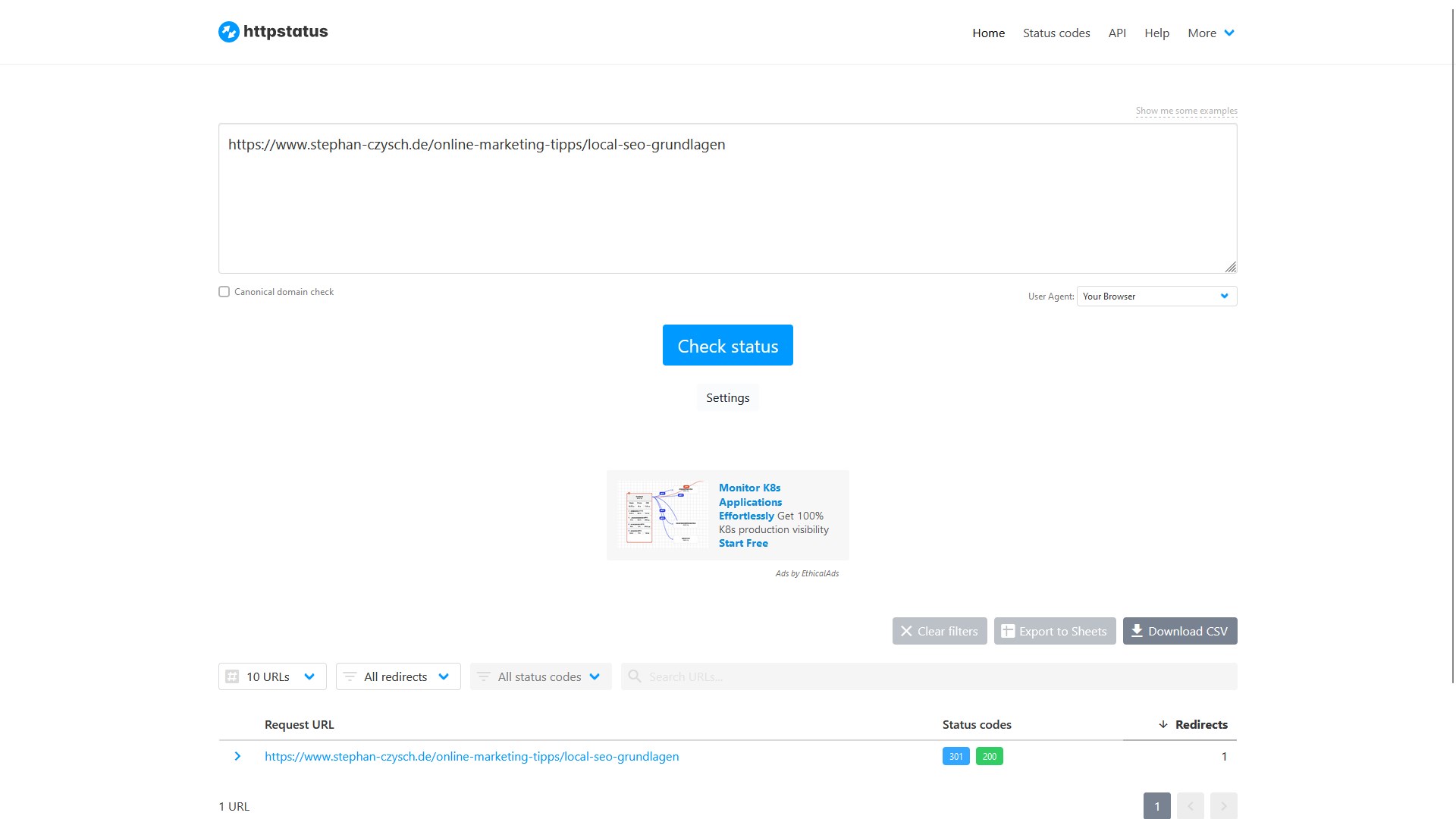
Und tatsächlich: bei der Überprüfung einzelner Seiten mit einem Tool wie httpstatus.io wird ersichtlich, dass die Seite per 301-Statuscode weitergeleitet wird.
Wie können Adressen indexiert werden?
Wenn eine Indexierung der von Google gerade als nicht-indexiert benannten Adressen gewünscht ist, dann muss ein neues Crawling der Seiten erreicht werden. Zwischen dem (wiederholten) Crawling einer Adresse können im Extremfall Monate liegen. Um die Wahrscheinlichkeit eines zeitnahen Crawlings zu erhöhen, gibt es die klassischen Wege:
- Aufnahme der Seite (mit einem aktuellen <lastmod>-Zeitpunkt) in eine XML-Sitemap
- Verbesserung der Verlinkung der Seite
- Einreichen der Seite über die Google Search Console
Während diese Varianten nur die Crawlingwahrscheinlichkeit erhöhen, bietet getIndexed einen entscheidenden Vorteil: Ein (fast) in Echtzeit stattfindendes Crawling der Seite.